


RDDs, DataFrames, and Datasets serve as the building blocks of Spark, each tailored for specific big data tasks. These components streamline data processing and simplify handling big data. Understanding them equips candidates to answer common Spark interview questions, including queries on resilient distributed datasets (RDDs), Spark DataFrames, and the Dataset API. Mastering lazy evaluation, DataFrame API, and fault tolerance ensures readiness for questions on big data tools and their role in data engineering.
At Aloa, we focus on delivering high-quality software projects using the best big data tools and practices. We collaborate with highly vetted partners and leverage cutting-edge frameworks to handle resource management, data analytics, and complex systems like Spark clusters and relational databases. Our team ensures efficient fault tolerance, data replication, and data partitions, enabling seamless project delivery. At Aloa, we ensure seamless collaboration with transparent processes and a dedicated team to guide you.
Employing best practices, we created this guide to help you excel in Spark interview questions. It explores understanding RDDs, DataFrames, and datasets and dives into advanced topics for Spark interviews. Ultimately, you’ll confidently address topics on Spark applications, operational elements, and directed acyclic graphs.
Let's get started!
Understanding RDDs, DataFrames, and Datasets Spark Interview Questions
Understanding RDDs, DataFrames, and Datasets is crucial for answering Spark interview questions effectively. These core Spark components form the foundation of big data processing. Let's explore their definitions, key features, and practical examples to prepare for questions targeting Spark’s building blocks and their real-world applications.
1. What are RDDs in Spark?
Resilient Distributed Datasets (RDDs) are immutable, distributed collections of objects that form the backbone of Apache Spark. RDDs enable efficient stream processing and batch processing through parallel computations. They handle a continuous data stream and support fault tolerance by automatically recreating lost data from their lineage.
Here are the characteristics of RDDs:
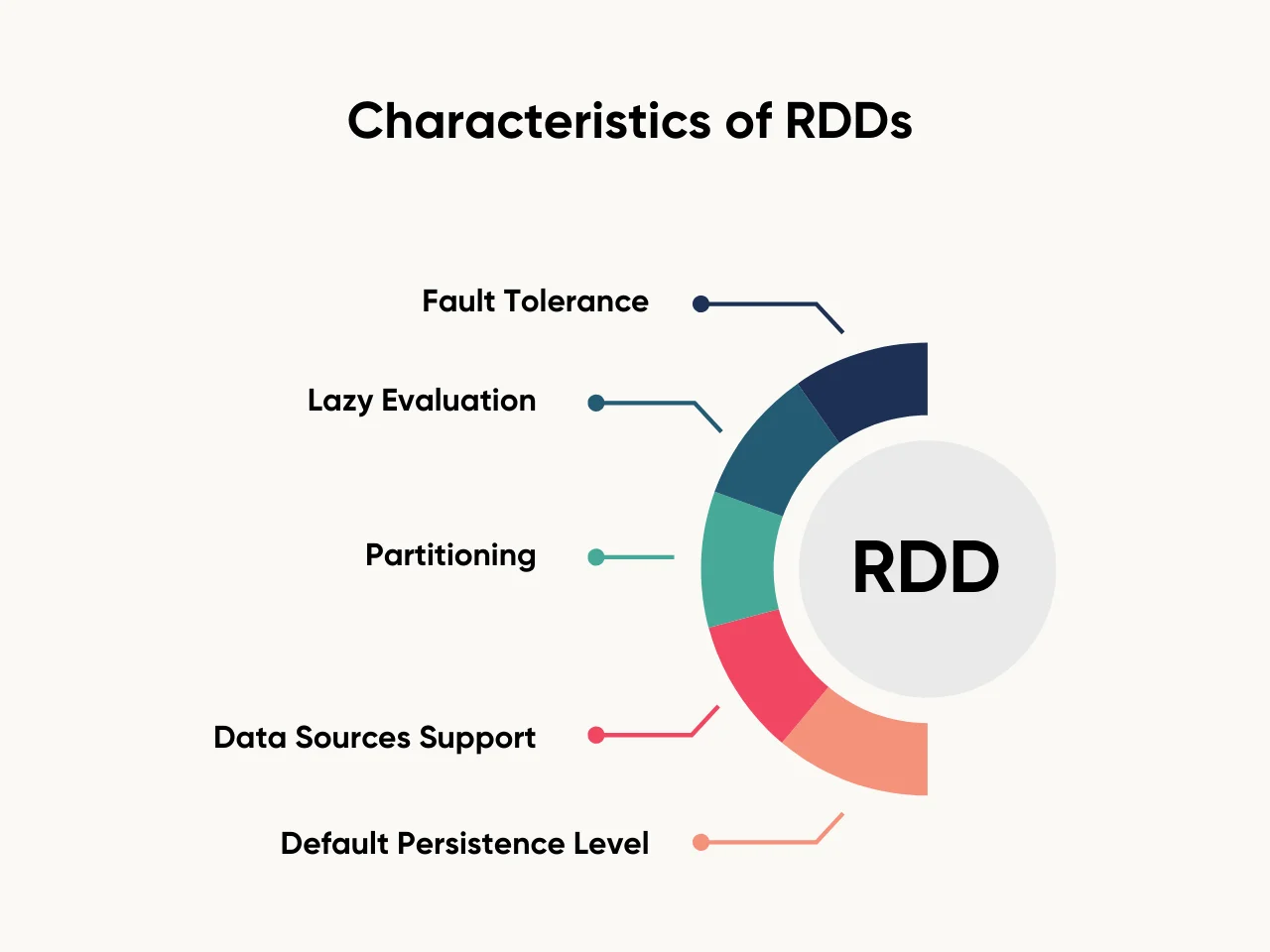
- Fault Tolerance: RDDs rebuild lost data using lineage information.
- Lazy Evaluation: Transformations occur only when actions trigger computation.
- Partitioning: Data splits into several partitions for efficient parallel processing.
- Data Sources Support: RDDs integrate with various data sources, including Hadoop MapReduce, text files, and external storage systems.
- Default Persistence Level: Stores intermediate results in memory or disk based on the spark driver program configuration.
The spark driver program defines RDDs using commands like sc.parallelize. For instance, you can create a new RDD from a text file and apply a transformation map to manipulate row objects or filter to extract a stream of data. The process optimizes memory management through Spark Core and handles workloads across the master node, worker nodes, and cluster manager.
RDDs work seamlessly with graph processing, machine learning libraries like Spark MLlib, and Cassandra connectors for advanced applications like graph algorithms or querying Parquet files. These capabilities make RDDs foundational for any Spark job requiring robust data structure handling.
2. What are DataFrames in Spark?
DataFrames are distributed collections of data organized into named columns, similar to tables in relational databases. They simplify working with structured input data, offering intuitive Spark SQL and programmatic operations APIs. Unlike RDDs, DataFrames provide schema awareness, improving performance and user experience. Here are the key features of DataFrames:
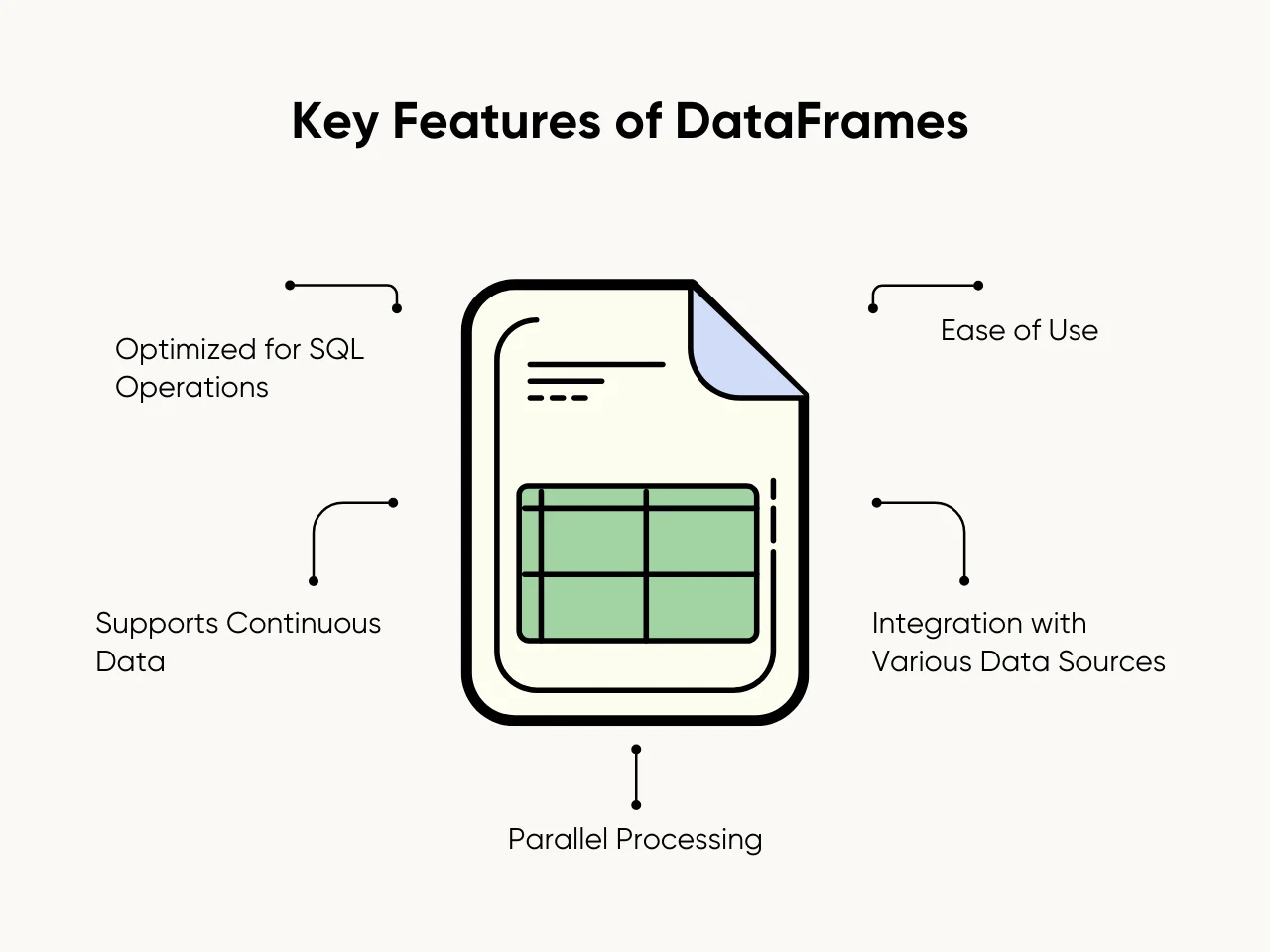
- Optimized for SQL Operations: DataFrames leverage Spark SQL and the Catalyst optimizer to execute queries efficiently.
- Ease of Use: APIs allow easier data manipulation than Spark RDD, enabling seamless transitions between SQL queries and functional programming.
- Integration with Various Data Sources: DataFrames load input streams from file systems, databases, or an existing RDD.
- Parallel Processing: Splits data into a number of partitions for distributed computation.
- Supports Continuous Data: Handles continuous data stream from real-time sources like Spark Streaming.
A Spark program initializes a DataFrame using commands like spark.read.csv("data.csv"). The data automatically maps to a collection of objects with schema detection. SQL-like operations such as select() or filter() refine the original data for specific analysis.
For instance, reading input streams from a CSV in an Apache Mesos cluster integrates seamlessly with file systems, offering high performance. DataFrames bridge structured data manipulation and real-time input data, ensuring flexibility across static and streaming use cases.
3. What are Datasets in Spark?
Datasets are strongly typed, distributed data collections that merge the advantages of RDDs and DataFrames. They provide a higher-level abstraction for structured data processing, ensuring type safety and compile-time error checking. This makes them ideal for applications that require strict schema enforcement and optimized execution.
Key Features of Datasets include:
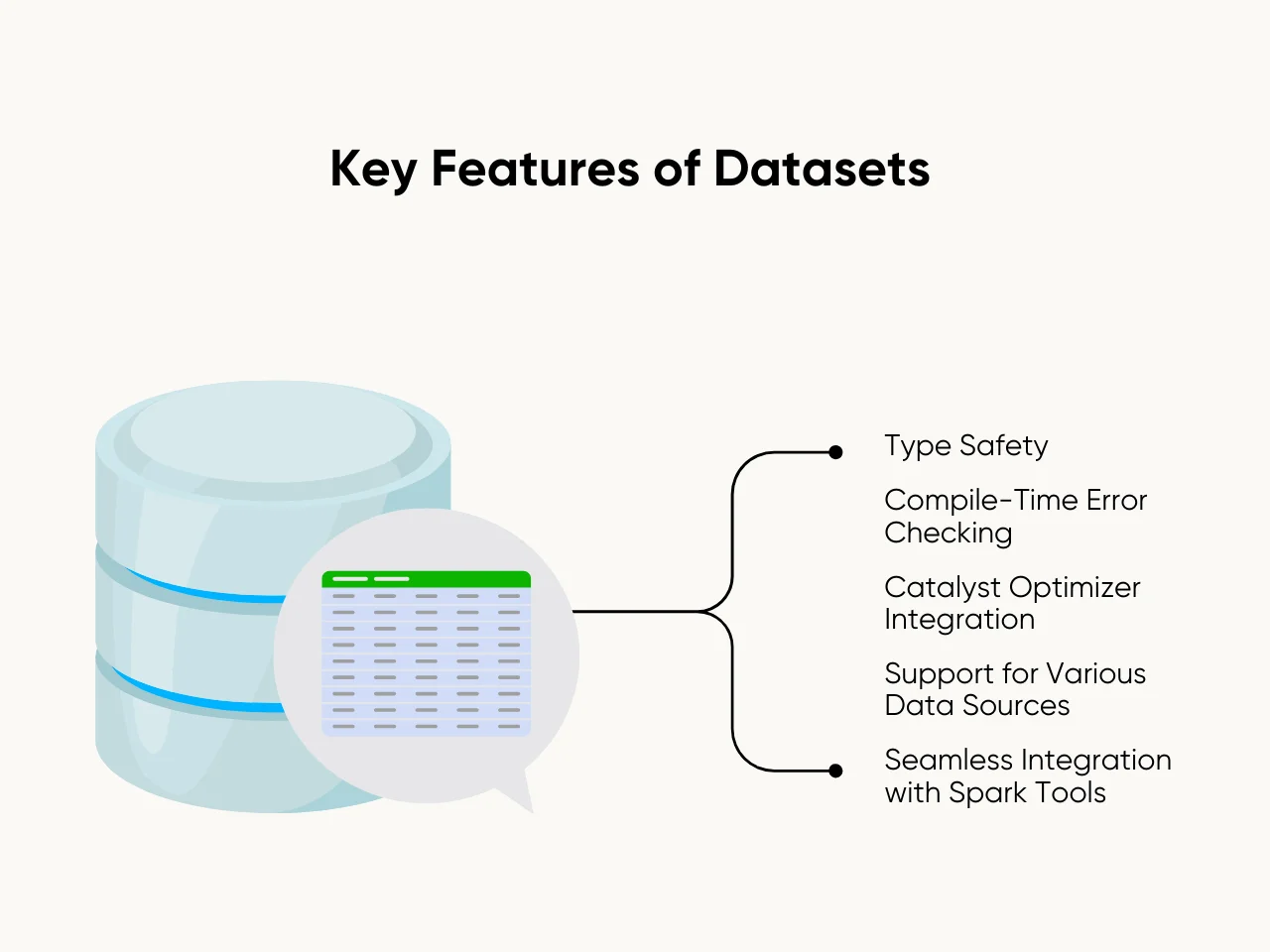
- Type Safety: Datasets ensure data adheres to specified types, reducing runtime errors.
- Compile-Time Error Checking: Developers catch mistakes early during code compilation.
- Catalyst Optimizer Integration: Enables high performance through efficient query execution plans.
- Support for Various Data Sources: Seamlessly read and write data from input streams, file systems, and external storage.
- Seamless Integration with Spark Tools: Works well with Spark SQL, Spark Streaming, and existing RDDs for diverse workflows.
In a Spark program, you can create a Dataset in Scala using the toDS() function. Converting a collection of objects into a Dataset allows structured operations such as filtering rows based on conditions or applying aggregations. Datasets also handle a continuous data stream, making them ideal for streaming tasks.
This combination of RDD flexibility and DataFrame usability ensures datasets are highly versatile for batch processing and real-time analytics and are supported seamlessly on platforms like Apache Mesos.
Common Interview Questions on RDDs, DataFrames, and Datasets
Answering Spark interview questions often involves comparing RDDs, DataFrames, and Datasets. Candidates must understand their key features, performance benefits, and ideal use cases. Here are commonly asked Spark interview questions to help you address scenarios involving lazy evaluation, fault tolerance, and efficient data processing.
4. What are the key differences between RDDs, DataFrames, and Datasets?
Understanding the differences between RDDs, DataFrames, and Datasets is essential when preparing for Spark interview questions. These three abstractions form the backbone of Apache Spark, each offering distinct advantages for specific use cases. A clear grasp of their differences ensures confident and informed answers during your interview.
Here are the main differences:
Each abstraction serves specific scenarios. RDDs work well for low-level operations or unstructured data. DataFrames excel at structured queries and SQL-like tasks. Datasets combine the best of both, providing type safety and optimized performance.
Choosing the right abstraction often depends on the task. Discussing scenarios where RDDs, DataFrames, or Datasets are preferable highlights your understanding during Spark interview questions. For example, RDDs suit complex transformations, while DataFrames simplify queries. Datasets add type safety for structured data.
5. When should you use RDDs over DataFrames or Datasets?
Understanding when to use RDDs instead of DataFrames or Datasets is crucial when tackling Spark interview questions. RDDs provide low-level control, making them ideal for transformations requiring fine-tuned operations or custom partitioning strategies. They excel in scenarios involving complex data manipulations or unstructured data that lack a defined schema. For instance, when working with binary data or processing real-time streams, RDDs allow greater flexibility compared to DataFrames or Datasets.
Spark interview questions emphasize how RDDs handle tasks that demand advanced control and non-structured operations. While DataFrames and Datasets offer schema-based optimizations and type safety, RDDs remain indispensable for use cases like iterative machine learning algorithms or bespoke partitioning scenarios. Preparing examples where RDDs outperform other abstractions will help you confidently demonstrate your expertise in Spark's core functionalities.
6. Explain how Catalyst Optimizer improves performance for DataFrames and Datasets
The Catalyst Optimizer is a crucial component to address in Spark interview questions about performance. As Spark’s query optimization engine, it plays a pivotal role in improving the efficiency of DataFrames and Datasets. This optimizer converts high-level queries into optimized execution plans, ensuring faster data processing and resource utilization.
The Catalyst Optimizer offers three main features:
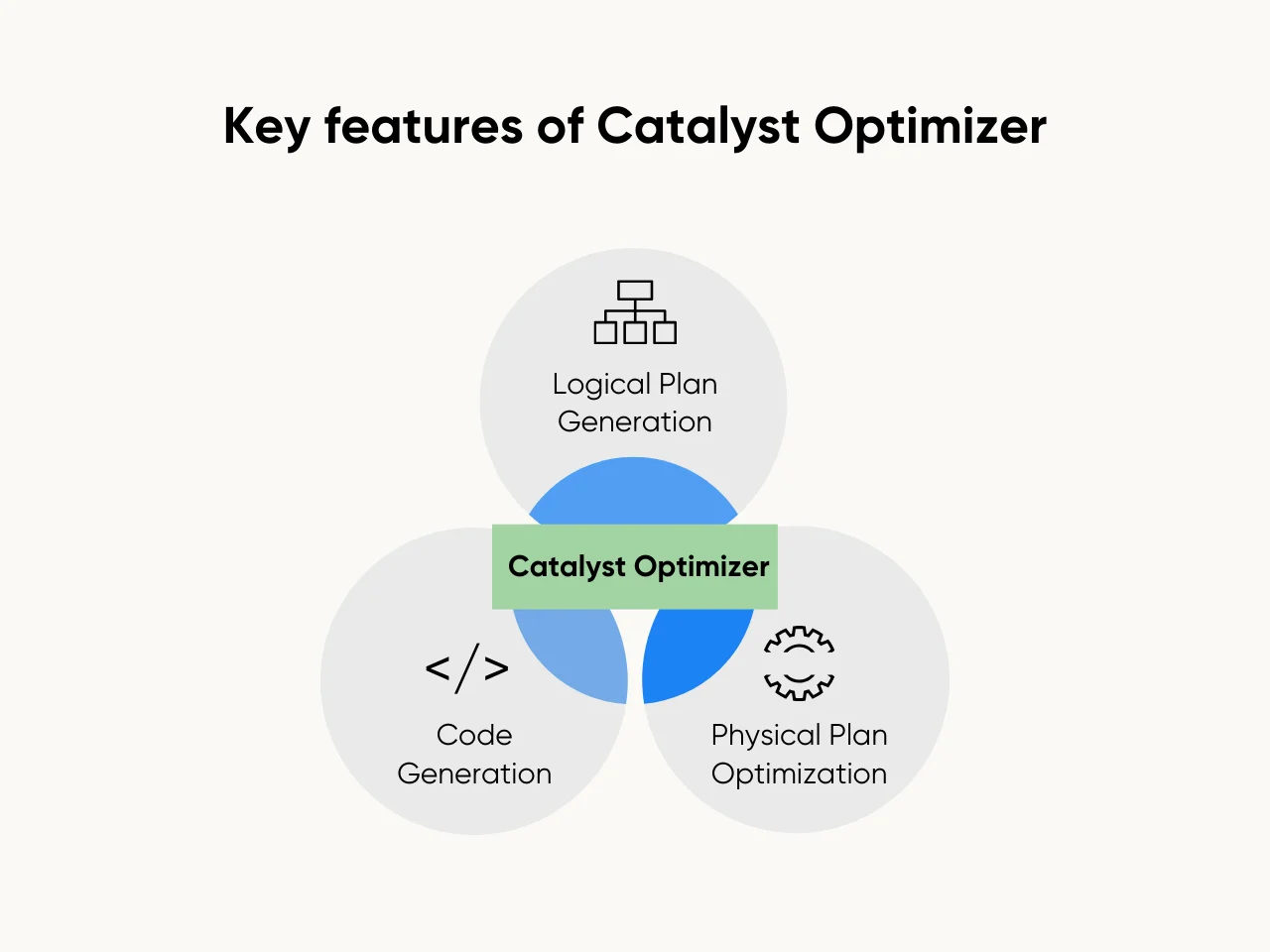
- Logical Plan Generation: It converts user queries into logical execution plans. These plans ensure operations follow an efficient sequence.
- Physical Plan Optimization: Catalyst refines logical plans into optimized physical execution strategies tailored for performance.
- Code Generation: It generates Java bytecode for transformations, enabling faster execution.
For example, when running SQL queries on DataFrames, Catalyst automatically rewrites the logical plan to execute faster. It applies advanced optimizations like predicate pushdown and joins reordering, reducing computation time and memory usage.
Mastering how Catalyst improves the performance of DataFrames and Datasets is key to answering Spark interview questions. Its ability to enhance query execution ensures scalability and efficiency in large-scale data operations. Demonstrating knowledge of Catalyst's role can set candidates apart in technical discussions.
Advanced Topics for Spark Interviews
Advanced Spark interview questions test optimization, resource management, and performance-tuning knowledge. Topics like the Catalyst optimizer, RDD lineage, and Tungsten engine highlight Spark’s advanced features. Prepare to discuss these topics, ensuring you stand out in interviews with comprehensive knowledge of Spark’s capabilities.
7. Explain the Role of Tungsten in Spark Optimization
Tungsten is Spark's in-memory computation engine, designed to improve execution performance. This project optimizes Spark's processing capabilities, particularly for Data Frames and Datasets. Tungsten achieves its goals by efficiently using CPU and memory resources, ensuring faster data processing. Understanding Tungsten can help you confidently answer Spark interview questions about performance tuning.
Here are the key features of Tungsten:
- Binary Processing: Tungsten encodes data in binary format, reducing the time required for serialization and deserialization, significantly improving processing speed.
- Cache-Aware Computation: It ensures optimal usage of CPU cache, enabling quicker access to frequently used data and reducing memory overhead.
- Reduced Garbage Collection: Tungsten minimizes object creation during computations, leading to less strain on the garbage collector and smoother execution.
Tungsten plays a vital role in improving the performance of complex DataFrame queries. Its ability to optimize physical execution plans ensures faster and more efficient query processing. When answering Spark coding interview questions, explain how Tungsten’s optimizations make Spark a powerful choice for handling large-scale data transformations. Mastering this topic can set you apart when tackling advanced Spark interview questions and answers.
8. How does Spark Handle Schema Inference for DataFrames and Datasets?
Schema inference allows Spark to automatically detect data types and structures when creating DataFrames and Datasets. This feature reduces the need for manual schema definitions, making it easier to process structured and semi-structured data. During DataFrame creation, Spark analyzes the input source, such as JSON or Parquet files, to infer column names, data types, and hierarchical structures.
Advantages of schema inference include:
- Simplified Data Handling: Eliminates the need for developers to define schemas explicitly, saving time and effort.
- Error Reduction: Ensures accurate detection of data types, minimizing runtime errors during transformations or queries.
- Streamlined Workflows: Improves efficiency when working with structured sources like JSON, CSV, or Parquet files.
For example, when loading a JSON file into a DataFrame, Spark examines the file's structure to generate a schema automatically. This process enables immediate querying and transformation without additional configurations. Understanding schema inference is crucial for answering Spark coding interview questions effectively. Mastery of this topic demonstrates your ability to leverage Spark's built-in capabilities for efficient data management.
9. What are the limitations of RDDs compared to DataFrames and Datasets?
While foundational to Spark, RDDs have several limitations that make them less efficient than DataFrames and Datasets in certain scenarios. These limitations often appear in Spark interview questions, as understanding them highlights the advantages of newer abstractions. Limitations of RDDs include:
- Lack of Schema Awareness: RDDs need built-in schema support. Processing without this support is less efficient, especially for structured or semi-structured data, as it requires additional coding to handle data formats manually.
- No Catalyst Optimization: RDDs do not benefit from Spark’s Catalyst optimizer, which enhances the performance of DataFrames and Datasets through query optimization. Without this support, RDD operations often take longer.
- Slower Performance for SQL-Like Operations: RDDs are less suited for SQL queries and relational operations. They require more complex coding and exhibit slower execution times than the optimized performance of DataFrames and Datasets.
These limitations emphasize why newer abstractions like DataFrames and Datasets have become the preferred choice for many data processing tasks. Addressing these differences during Apache Spark interview questions demonstrates your understanding of Spark’s evolution and ability to choose the right abstraction for the task. Recognizing when RDDs may still be helpful, such as for unstructured data or custom partitioning, adds depth to your responses.
Key Takeaway
Preparing for Spark interviews demands a strong grasp of RDDs, DataFrames, and Datasets. These three components serve as the backbone of Apache Spark, and understanding their features ensures confidence when tackling Spark interview questions. RDDs offer low-level control, DataFrames simplifies data handling with schema-based optimizations, and Datasets provide type safety for structured data.
Leverage advanced developments in information technology to deepen your understanding of Spark’s optimizations. Features like Catalyst Optimizer and Tungsten execution engine enhance Spark’s performance and efficiency. Highlighting how these tools simplify big data processing and set you apart when answering spark interview questions and answers. Demonstrating practical knowledge, such as using schema inference or handling skewed data, reflects your ability to manage real-world challenges effectively.
Are you ready to ace your Spark interview questions? At Aloa, we help professionals stay updated on emerging technologies and prepare for success in competitive fields. Let Aloa guide you in developing the technical and strategic skills needed to thrive in the evolving tech landscape. Explore our resources to gain a competitive edge and position yourself as a top candidate for your next interview.









